クリーンアーキテクチャ概要

ソフトウェアアーキテクチャの 1 つとして有力な設計手法・アーキテクチャパターンであるクリーンアーキテクチャの概要を解説します。
目次
クリーンアーキテクチャの概要
クリーンアーキテクチャとは
クリーンアーキテクチャとは、Robert C. Martin(Uncle Bob)氏が提唱した、ソフトウェアの設計手法・アーキテクチャパターンの 1 つです。
クリーンアーキテクチャの主な目的は、以下です。
- 疎結合になり、テストしやすい。
- 技術選択を後から変更しやすい。
- ドメインのロジックの見通しがよくなる。
- 大規模・長期プロジェクトで特に力を発揮する。
クリーンアーキテクチャの考え方を採用することで「変更に強く、テストしやすく、長期運用に耐えうるシステム」を作ることが可能になります。
この記事では、クリーンアーキテクチャの概要について紹介します。

クリーンアーキテクチャの基礎となる 4 層
クリーンアーキテクチャ では、エンティティ (Entities) / ユースケース (Use Cases) / インターフェースアダプター (Interface Adapters) / フレームワークとドライバー (Frameworks & Drivers) という 4 つの代表的な層(レイヤ)があります。
クリーンアーキテクチャは、以下のような図で表現されます。まずは、それぞれの層について概要を説明していきます。

エンティティ (Entities)
エンティティ (Entities) は、企業のビジネスルールのデータをまとめてカプセル化したデータ構造のことを言います。このエンティティは、メソッドを持ったオブジェクトなどであり、企業の様々なアプリケーションから利用されるものです。
機能の追加や UI の変更があっても、ビジネス上で中核となるデータ構造は比較的安定しているため、エンティティは外側の変更の影響を受けにくい層になります。
ユースケース (Use Cases)
ユースケース (Use Cases) は、アプリケーション固有のビジネスルールを定義する層です。ユースケースでは、エンティティのデータをもとに目的を達成するための機能を実装します。
この層は、データベースや UI、その他のフレームワークといった外部の変更から影響を受けることはありません。例えば、データベースが Oracle だとしても、PostgreSQL であったとしても、その上でユースケースとして実装する機能にとってはどちらでもいいのです。
ただし、アプリケーションの画面などの操作変更により、ユースケースに手を加えなければいけないということはあり得ます。
インターフェースアダプター (Interface Adapters)
インターフェースアダプター (Interface Adapters) は、エンティティやユースケースにとって便利なデータフォーマットと、データベースや UI などにとって便利なフォーマットとの間の変換をするためのアダプターです。
インタフェースアダプター層が変換を担うため、ユースケースの層では、外部のデータ構造を意識する必要がなくなります。
フレームワークとドライバー (Frameworks & Drivers)
フレームワークとドライバー (Frameworks & Drivers) は、円の最も外側で最も詳細な部分です。これらは、DB や UI 等の外部インターフェースに関する機能です。
例えば、DB アクセス用のライブラリやデバイスのための制御プログラムなどがこの層に該当します。
SOLID 原則とクリーンアーキテクチャ
SOLID 原則
クリーンアーキテクチャを理解する上で重要な原則に「SOLID 原則」があります。SOLID とは、Robert C. Martin(Uncle Bob)氏が提唱した 保守性と拡張性の高い設計を行うための 5 つの原則 をまとめたものです。
| 原則 | 名称 | 概要 |
|---|---|---|
| S | 単一責任の原則 (SRP: Single Responsibility Principle) | 各モジュールを変更する理由がたった 1 つだけになるようにすること |
| O | 開放閉鎖の原則 (OCP: Open-Closed Principle) | 既存のコード変更よりも新しいコードの追加によってシステムの変更ができるようにすること |
| L | リスコフの置換原則 (LSP: Liskov Substitution Principle) | インターフェースで抽象化されたコンポーネントで安全に交換可能となっていること |
| I | インターフェース分離の法則 (ISP: Interface Segregation Principle) | 用途ごとにインターフェースが分離して定義されていること |
| D | 依存性逆転の原則 (DIP: Dependency Inversion Principle) | 上位レベルの実装コードが下位レベルの詳細の実装コードに依存するのではなく、逆に詳細側が上位の方針に依存するべきであること |
各原則の細かな説明についてはしませんが、SOLID 原則の中でもクリーンアーキテクチャで特に重要な原則である「依存性逆転の法則 (DIP)」については、この記事で考え方を紹介します。
その他の設計原則については、書籍「Clean Architecture 達人に学ぶソフトウェアの構造と設計」を参考にしてください。
クリーンアーキテクチャで特に重要な依存性の方向(DIP)
上記で紹介した SOLID 原則は、いずれも重要な設計原則ですが、その中でもクリーンアーキテクチャを考えるうえで特に重要な原則が「依存性逆転の原則 (DIP: Dependency Inversion Principle)」です。以降、DIPと略します。
プログラミングでは、何も考えずに実装を始めると図でいう外側に依存するようなプログラミングをよくしてしまいます。しかし、DIP では、依存の向きを図における内側、つまり Entities 方向に向けることが重要であると言っています。
依存方向とは、「どちらの変更がどちらに影響するか」を示します。Python を例にすると A が B をインポートしているとき、A は B の変更の影響を受けるため A は B に依存していると言います。矢印としては A → B となります。
import module
例えば、上記例のように module モジュールをインポートしているプログラムは module に依存します。これは module での変更が当該プログラムに影響を与える可能性があるということです。
クリーンアーキテクチャにおいては、Entities や UseCases といった、企業のビジネスルールやアプリケーションのルールが、詳細である外側の層から影響を受けてはいけないということを言っています。
なかなかイメージが難しいと思いますので、DIP に反する依存関係の例と DIP に従っている例を見ながら考えてみましょう。
DIP に反する依存関係の例
以降では、ユーザー情報を DB に登録するような例を使って紹介していきます。まずは、依存関係が DIP に反する例を見てみましょう。
以下は、ユーザー情報を定義した User クラスがあり、CreateUserUseCase クラスで PostgreSQL にユーザー登録している場合です。
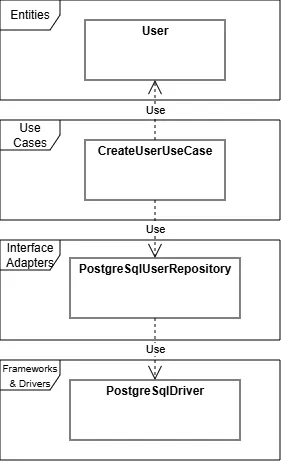
この例では、CreateUserUseCase → PostgreSqlUserRepository → PostgreSqlDriver というように内側から外側に向かう依存関係となっています。
この場合、PostgreSqlDriver が変更されると PostgreSqlUserRepository の変更が必要になる可能性があり、その次には、CreateUserUseCase クラスの実装まで変更が波及する可能性があります。
詳細である DB 管理が変更されても、ユースケース自体が何も変更されているわけでもないのにプログラムの修正が必要になってしまうかもしれないわけです。
依存関係の理想(DIP)
では、次に DIP がどのようにこの問題を解決するのかを見てみましょう。以下が、DIPを考慮した場合のクラス図の例です。
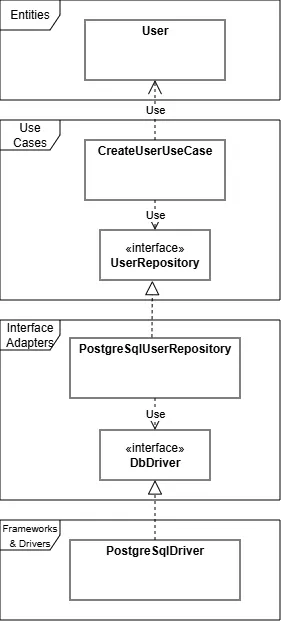
抽象化されたインターフェース
DIP でポイントとなるのは、抽象化されたインターフェースの使用です。
例では、UseCases 層で Interface Adapters 層 で実装するべきインターフェース (UserRepository) を定義します。Interface Adapters 層側では、そのインターフェースに従うように PostgreSqlUserRepository の具体的な実装を行います。UseCases 層では、CreateUserUseCase → UserRepository に依存(矢印)が向いているように、具体的な実装ではなく抽象化されたインターフェースに依存します。
同様に、Interface Adapters 層でもインターフェース (DbDriver) を定義し、Frameworks & Drivers 層の PostgreSqlDriver が、そのインターフェースに従って具体的な実装を行います。PostgreSqlUserRepository は 抽象化されたインターフェースである DbDriver に依存します。
この例で、各層の間の矢印を確認してみてください。先ほどの DIP に反した例とは依存関係の矢印が逆向きになっています。これが、依存性逆転と言われる理由です。この逆転のためには、抽象化されたインターフェースがポイントとなります。
依存性の注入
DIP での構成が優れているところは、各層が自身の層で定義したインターフェースで定義された機能の仕様のみ知っておけばよいということです。ここで、仕様と言っているのは、例えば、メソッドの引数、戻り値、それらの型だと思ってください。外側の具体的実装は、そのインターフェースに従うように実装されるため、具体的な詳細まで知る必要がありません。
例では PostgreSql を想定したクラスを例示していますが、UserRepository というインターフェースに従ったクラス(例えば、OracleUserRepository や MySqlUserRepository など)を作成すれば、そのクラスはインターフェース仕様で決められた引数や戻り値、型を持つ機能を実装しているため、付け替えも容易です。
インターフェースを使うため、テスト時にドライバーやスタブを用意しやすい点も重要な特徴です。また、DBMS などの詳細技術が決まっていない段階では、技術の選択を後回しにしてビジネスロジックの開発を進められるという利点があります。
内側の関数やメソッドでは、抽象化されたインターフェースを呼び出すように開発されるため、具体的にインスタンス化するクラスを変更するだけで簡単に実装の変更ができます。このようにどの具象クラスを使うかを外側から渡す方法を「依存性の注入(DI: Dependency Injection)」と言います。DI は、DIP の考え方を現実のコードで実現する代表的な手法の 1 つです。
例のクラス図での UseCases 層と Interface Adapters 層の間の関係性をイメージして、実際に簡単なコードイメージを見てみましょう。
# interface.py
from abc import ABC, abstractmethod
class UserRepository(ABC):
@abstractmethod
def save(self, user_name: str) -> None:
...# postgresql_repository.py
from interface import UserRepository
class PostgreSqlUserRepository(UserRepository):
def save(self, user_name: str) -> None:
print(f"[PostgreSQL] save user: {user_name}")
# ※本当は具体的な登録処理が実行される# usecase.py
from interface import UserRepository
class CreateUserUseCase:
def __init__(self, repo: UserRepository):
self.repo = repo # 抽象に依存
def execute(self, user_name: str):
# 具体的なDB処理は知らない
self.repo.save(user_name)# main.py
from usecase import CreateUserUseCase
from postgresql_repository import PostgreSqlUserRepository
def main():
repo = PostgreSqlUserRepository() # ここで具体を選択(OracleUserRepository に変えれば Oracle に切替が簡単にできる)
usecase = CreateUserUseCase(repo) # 依存性の注入(内側へ注入)
usecase.execute("Taro")
if __name__ == "__main__":
main()UserRepository という抽象クラスをインターフェースとして用意し、それを継承して、PostgreSqlUserRepository を作成しています。CreateUserUseCase クラスは実際にユーザーを作成・登録するためのユースケースだと思ってください。
上記でのポイントは、CreateUserUseCase のコンストラクタ __init__ が、抽象の UserRepository を引数に取っている点です。これは、ユースケースが、具体的に PostgreSQL を使うのか、Oracle を使うのかといった具体的なことは全く意識していないということを意味しています。
具体的にどの実装を使うかはエントリポイントである main 関数で選択しています。CreateUserUseCase のインスタンス化で PostgreSqlUserRepository のインスタンスを渡しています。これが、依存性を注入している部分です。
このようにしておくと DB を Oracle に変えたければ、UserRepository を実装した OracleUserRepository を作成し、main 関数でインスタン化するクラスを変えれば、技術の付け替えが完了します。この時には、main 関数のみに変更を加えればよく、 usecase.py を変更する必要が全くないことが非常に重要なことです。
上記で見てきたように DIP の考え方に従うロジックの見通しがよくなり、テストがしやすく、技術選択も後から変更しやすいシステムを構築できます。これにより、特に大規模・長期のプロジェクトでは、改修・維持・管理といった負担が軽減されます。
依存関係の現実
DIP の考え方について紹介しましたが、現実の場面では少し柔軟性を持って考える必要が出てくる場合があります。以下は、Frameworks & Drivers の層として、PostgreSQL を扱うためのモジュールである psycopg2 を使っている例です。
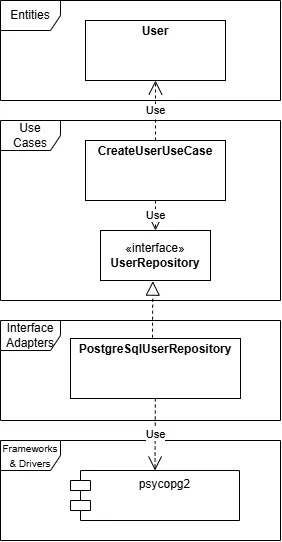
psycopg2 は、コミュニティで開発されているため、自分たちで定義した Interface Adapters 層のインターフェースに従うように機能を実装してもらうことは困難です。そのため、アダプターから psycopg2 への依存はどうしても発生します。
ただし、この依存は外側の詳細同士の依存であり、内側の Entity や UseCase からは、psycopg2 が見えていない限り、DIP の本質は守られていると言えます。
クリーンアーキテクチャでは、DIP を完全に実現することが目的ではなく、重要なビジネスルール(Entity や UseCase)を外部の詳細から守ることがより重要です。
もちろん Frameworks & Drivers 層の機能も自分たちで開発する場合は、DIP に従うように考えるのがベストですが、世の中にある便利なモジュールを使うことは、開発コストを抑えることができて合理的な場合も多くあります。原則にこだわりすぎるのではなく、柔軟な考え方でアーキテクチャを検討するようにしましょう。
ドメイン駆動設計(DDD)との関係
システムの設計では、ドメイン駆動設計(DDD: Domain Driven Design)という設計思想があります。エリック・エヴァンス(Eric Evans)氏が提唱したもので、クリーンアーキテクチャと一緒に語られることが多く、混同されやすいため簡単に整理しておきます。
ドメイン駆動設計は、複雑なビジネスドメインをどのように定義し、正しくモデル化することを目的にした設計思想のことです。一方で、クリーンアーキテクチャは、主にソフトウェアをどのような構造で分割するかといった、システムアーキテクチャの設計手法になります。
| クリーンアーキテクチャ | ドメイン駆動設計(DDD) |
|---|---|
| アプリケーションの構造を整理することが目的 | ビジネスドメインを正しく表現することが目的 |
| 層構造や依存方向を重視 | ドメインモデルの表現を重視 |
| システムアーキテクチャの話 | モデリングの考え方(設計思想) |
| 多くの種類のアプリケーションに適用しやすい | 大規模・複雑なドメインで特に有効 |
ドメイン駆動設計の文脈で出てくる概念をアーキテクチャとして実現する際に、クリーンアーキテクチャの考え方は適用しやすいため、両者は目的は明確に異なりますが、併用されて力を発揮することが多いです。
ドメイン駆動設計に関する書籍としては「エリック・エヴァンスのドメイン駆動設計」「ドメイン駆動設計をはじめよう」「ドメイン駆動設計入門 ボトムアップでわかる!ドメイン駆動設計の基本」を参考にしてみてください。



まとめ
ソフトウェアアーキテクチャの 1 つとして有力なクリーンアーキテクチャの概要を解説しました。クリーンアーキテクチャの考え方を採用すると変更に強い、長期運用に耐えうるシステムの開発が可能となります。
この記事では、クリーンアーキテクチャの基本的な概念である 4 つの層の考え方や、アーキテクチャ設計原則である SOLID 原則を紹介しました。また、設計原則の中でも特に中心となる「依存性逆転の原則 (DIP: Dependency Inversion Principle)」について少し深堀をして紹介しました。
プログラミングは文法を覚えるだけでは、良いシステムを開発できるとは限りません。システムアーキテクチャの理解は、学習コストも高く、解釈も人により微妙に異なる場合がある領域かと私は思っています。また、正解のアーキテクチャが決まっているわけではなく、適用するシステムの特徴に合わせて最適なアーキテクチャを十分に検討する必要があるため、非常に難しい領域だと思っています。
この記事を参考にしていただいて、自分の中でシステムアーキテクチャの最適な考え方や理解に落とし込んでいただければと思います。

プログラミング言語はこれまでC、C++、JAVA等を扱ってきましたが、最近では特に機械学習等の分析でも注目されているPythonについてとても興味をもって取り組んでいます。これまでの経験をもとに、Pythonに興味を持つ方のお役に立てるような情報を発信していきたいと思います。どうぞよろしくお願いいたします。
※キャラクターデザイン:ゼイルン様