【Stable Diffusion WebUI】ローカル環境の構築方法と基本的な使い方

画像生成AIソフトウェアの一種であるStable Diffusion WebUIをローカル環境で動作させるための方法について解説します。
Stable Diffusion WebUI
Stable Diffusionは、入力したテキストをもとに画像生成が可能な生成AI(Generative AI)ソフトウェアの一種です。利用者は、Stable Diffusionに生成したい画像に関するテキストを入力することで簡単に画像を生成することができます。
Stable Diffusionには「Stable Diffusion WebUI」というブラウザ上で画像生成できるツールがあり、AUTOMATIC1111というgithubアカウントで公開されています。
Stable Diffusion WebUIは、Google Colabでも使うことができますが、ご自身でグラフィックボードの搭載したPCがある場合には、ローカルに環境を作ってしまうと便利です。
本記事では、Stable Diffusion WebUIをローカル環境にインストールして使う方法について紹介したいと思います。
Stable Diffusion WebUIのローカル環境構築方法
説明の前提スペック
本記事では、私が保有している以下GPU搭載のPCを前提にローカル環境を構築していく方法を紹介していきます。
- OS:Windows 10 Pro
- CPU:Intel(R) Core(TM) i9-9900K CPU
- メモリ:32GB
- GPU:NVIDIA GeForce RTX 2080 Ti (専用GPUメモリ11GB)
Stable Diffusionを快適に使いたい場合は、GPUメモリ12GB以上のGPU(RTX3060以上)が推奨されるようです。私のPCは少し前に購入したPCなので少し性能的には劣っていますが、Stable Diffusionが実行可能であることは確認しています。
前提ソフトウェア
Stable Diffusionを動作させるためには以下ソフトウェアを用意します。
- Python 3.10.6
- Git
- NVIDA CUDA 11.7
- NVIDA cuDNN 8.9.3 for CUDA 11.x
Python
Stable Diffusion WebUIは、本記事執筆時点でPython3.10.6が推奨となっているので、指定Pythonバージョンをインストールします。Python3.10.6はこちらのダウンロードページの「Looking for a specific release?」にある一覧からダウンロードするようにしてください。

Pythonのインストール自体は「Pythonのインストール方法(Windows)」を参考にしていただいてバージョンやフォルダは読み替えてください。今回は、C:\Python\Python310_6にPython3.10.6をインストールしてvenvでStable Diffusion用の環境を作成します。
Git
Stable Diffusion WebUIを、今回はgithubからクローンして構築します。そのため、PCにGitをインストールしておく必要があります。
Gitのインストールは「Gitのインストール方法(Windows)」を参考にしてもらえればと思います。基本的にはインストーラを進めていくだけでインストール可能です。
NVIDIA CUDA, cuDNN
NVIDAのGPUを使う場合には、CUDA(Compute Unified Device Architecture)やcuDNN(CUDA Deep Neural Network)というGPUを用いて並列計算を行うためのソフトウェア開発・実行環境やライブラリを用意します。
CUDAやcuDNNに関するインストール方法については「CUDA/cuDNNのインストール方法(Windows)」を参考にしてください。
以降の説明では、今回対象の環境にあわせてCUDA 11.8、 cuDNN 8.9.3 for CUDA 11.xをインストールした状態を前提とします。
Stable Diffusion WebUIのインストール
Stable Diffusionのダウンロード
Stable Diffusion WebUIは以下のgithubで公開されています。
https://github.com/AUTOMATIC1111/stable-diffusion-webui
以降の説明では、以下リポジトリをgit cloneで取得して環境構築する方法を紹介していきます。
https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
Stable Diffusion WebUIのクローン
Stable Diffusion WebUIのクローンを作成するためのフォルダを任意の場所に作成します。なお、modelデータ等で容量を使いますので、例えばCドライブ、Dドライブなどのようにシステムトライブとデータドライブを分けている場合は、Dドライブ等のデータドライブに配置することをおすすめします。
以降では「D:\AI」というフォルダを作成して、その下にクローンします。お使いの環境によって読み替えていただければと思います。コマンドプロンプトで以下のように対象フォルダへ移動します。
cd /D D:\AI
git cloneコマンドで、Stable DiffusionWebUIをクローンします。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
クローンが成功すると「D:\AI\stable-diffusion-webui」に各種ファイルが生成されます。
Python実行仮想環境の作成(venv)
Stable Diffusionを実行するためのPython環境を準備します。まずはクローンしたフォルダに移動します。
cd D:\AI\stable-diffusion-webui
以下コマンドを実行して仮想環境を作成します。実行するとvenvというフォルダが作成されて、その配下にPython3.10.6の環境が作成されます。
C:\Python\Python310_6\python.exe -m venv venv
参考までにコマンドプロンプトで作成したvenv環境に入りたい場合は、以下のようにactivate.batで入ることができます。
D:\AI\stable-diffusion-webui\venv\Scripts\activate.bat
以下のように(venv)という表示が出たら環境に入れていることになります。

もし個別にパッケージをpipインストールしたい場合は、このコマンドで環境に入ってから実行することで他に影響を与えず環境に変更を加えることができます。
環境から出るにはdeactivate.batを実行します。
D:\AI\stable-diffusion-webui>D:\AI\stable-diffusion-webui\venv\Scripts\deactivate.bat
Stable Diffusion WebUIの必要コンポーネントインストールと実行
Stable Diffusion WebUIは「D:\AI\stable-diffusion-webui\webui-user.bat」を実行することで、必要なコンポーネントのインストールと実行ができます。いくつかwebui-user.batに変更を加える箇所があるので説明します。
webui-user.batをテキストエディタで開いて、以下のように修正してください。
@echo off set PYTHON=D:\AI\stable-diffusion-webui\venv\Scripts\python.exe set GIT= set VENV_DIR=D:\AI\stable-diffusion-webui\venv set COMMANDLINE_ARGS=--autolaunch --xformers call webui.bat
set PYTHON
Pythonの実行ファイルを指定します。今回はvenvで環境を作成しましたので、venv以下のpython.exeを指定しています。
set VENV_DIR
Python仮想環境の位置を指定します。ここに指定することにより実行時の環境を指定できます。また、必要なインストールは指定した環境に対して実行されます。
set COMMANDLINE_ARGS
実行時のコマンドライン引数を指定します。いくつか代表的な引数について説明します。
| 引数 | 概要 |
|---|---|
| –autolaunch | webui-user.batを実行時に自動でStable Diffusion WebUIが実行されます。 |
| –precision full | 16系※のグラフィックボードを使用している場合には指定が必要のようです。 ※1660Ti等のように16から始まるグラフィックボードです。 |
| –no-half | 同上 |
| –lowvram | グラフィックボードの性能が低い場合は、指定してみてください。 |
| –xformers | xformersという追加ライブラリを使用します。画像生成速度の大幅な向上や使用するVRAM量の削減が期待できます。 |
上記の変更を加えたら、「webui-user.bat」をダブルクリックで実行してください。以下のようにPyTorch等の必要なコンポーネントのインストールが開始されます。環境により少し時間がかかるかもしれません。

コマンドプロンプトに表示されている情報を見るとStable Diffusionのバージョンはv1.5.1で、PyTorch2.0.1+cu118のインストールがされています。cu118ということで、CUDAバージョンは11.8であるのが適切かと思います。環境について整合がとれているかは確認してみましょう。
以下のような画面が表示されれば、Stable Diffusion WebUI のインストールは完了です。
コマンドプロンプトは処理に必要ですので実行中は消さないようにしてください。また、次回実行の際にも、webui-user.batを実行してもらえれば画面が表示されます。2回目以降はインストール作業等がないのですぐに開かれるかと思います。
以降では、公開されているモデルを取得してStable Diffusionを使う基本的な使い方を簡単に紹介します。
Stable Diffusion WebUIの基本的な使い方
モデルの準備
Stable Diffusionの画面左上のプルダウンでは、画像生成に使用するモデルを選択することができます。デフォルトで入っているのは「v1-5pruned-emaonly.safetensors」というモデルです。

画像の生成結果はモデルによって変わります。例えばですが、アニメ調の画像を生成するのであれば、それに合ったモデルが必要です。モデルの取得先としては、Civitai(https://civitai.com/)が有名です。Civitaiでは様々なモデルを見つけることができます。
今回以降の説明では、Civitaiで上位に出てきた「DreamShaper」というモデルを使ってみます。DreamShaperは、人物や背景を、リアル調・イラスト調を問わず生成できるモデルのようで汎用性が高いモデルのようです。
モデルファイルを取得したら環境を準備したmodels\Stable-diffusionフォルダの下に配置してください。今回の環境でいうと「D:\AI\stable-diffusion-webui-base\models\Stable-diffusion」になります。モデルファイルを配置した後に画面左上の更新ボタンを押すと、プルダウンに配置したモデルを選択することができます。

Civitaiのモデルについては、商用で使ったり公開したりする場合には注意が必要です。ダウンロードページの右下の方に以下のようなアイコンで禁止項目が表示されています。禁止事項のいずれかのアイコンをクリックすると規約が表示されます。以下は今回使用したDreamShperでの例です。

「Sell this model or merges using this model (該当のモデルデータ、およびマージ素材として使って作成した新しいモデルデータの販売)」が禁止されていますが、他については許可がされています。
DreamShaperは、比較的許可されていることが多いように思いますが、例えば「Use the model without crediting the creator (モデルを作者のクレジット表記なしで使用すること)」が禁止されている場合、生成した画像をSNS等に投稿するときなどには必ずモデルデータを明記する必要があります。
Civitaiのモデルを活用する際には、よく確認してモデルやモデルから生成した画像を扱うようにしてください。
Stable Diffusion WebUIの基本的な使い方
Stable Diffusion WebUIの基本的な使い方を見ていきましょう。テキストから画像を生成する基本的な「txt2img」タブの部分に絞って説明します。
画面構成
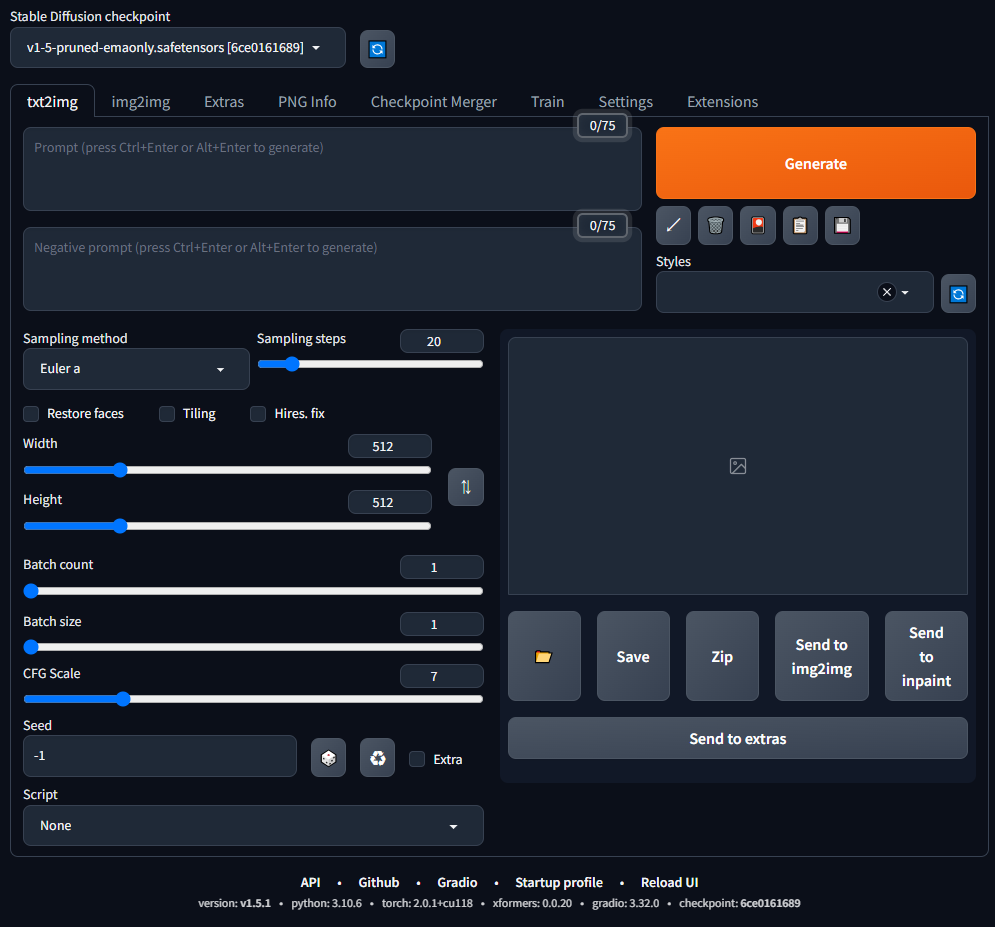
Stable Diffusion WebUIの[txt2img]タブの画面構成としては以下のような項目になっています。

① モデル選択
画像生成に使用するモデルを選択します。
② プロンプト(Prompt)
生成したい画像に関するテキスト情報を記載します。0/75とありますが、これは入力できる文字列の数です。
③ ネガティブプロンプト(Negative Prompt)
生成したい画像に含めたくないテキスト情報を記載します。0/75とありますが、これは入力できる文字列の数です。
④ 各種パラメータ
画像生成に関する各種パラメータを設定します。まず、実行してみる場合には特に変更する必要はありません。出力結果を調整する際に色々と変更を試してみてください。
| 項目 | 内容 |
|---|---|
| Sampling method | ノイズを除去(サンプリング)するときのアルゴリズム (使用するモデルに指定があれば、それに従うのがよいでしょう) |
| Sampling steps | ノイズを除去(サンプリング)する回数 |
| Restore faces | 顔が崩れる場合の補正をかける (必ずきれいになるとは限らない) |
| Tilling | タイル状に並べる |
| Hires. fix | 解像度を上げる設定ができる |
| Width, Height | 出力画像の横幅(Width)、高さ(Height) |
| Batch count | バッチ回数 |
| Batch size | 1バッチあたりの画像枚数 |
| CFG Scale | CFG(Classifier-Free-Guidance)という、どれだけプロンプトに近いイラストを生成するかを調整する値 (大きい方がプロンプトに沿った出力になるが、画像が崩れる可能性が高くなる) |
| Seed | 値によって出力が決定 (-1の場合は、実行毎にランダムに設定) |
| Script | プロンプトの組み合わせや各種パラメータ調整に役立つスクリプト (Prompt matrix, Prompts from file of text box, X/Y/Z plotの3つが用意されている) |
⑤ 実行
「Generate」ボタンを押すことで画像出力をすることができます。
⑥ 出力エリア
設定したプロンプトに基づく出力画像が表示されます。
なお、出力画像ファイルはoutputsフォルダに実行日付毎に出力されます。今回の環境でいうと「D:\AI\stable-diffusion-webui\outputs」です。
画像生成をしてみる
では、実際に使ってみましょう。なんでもいいのですが、適当に「ロボットが空を飛んでいる画像」を生成してみようと思います。モデルとしては「DreamShaper」を使います。
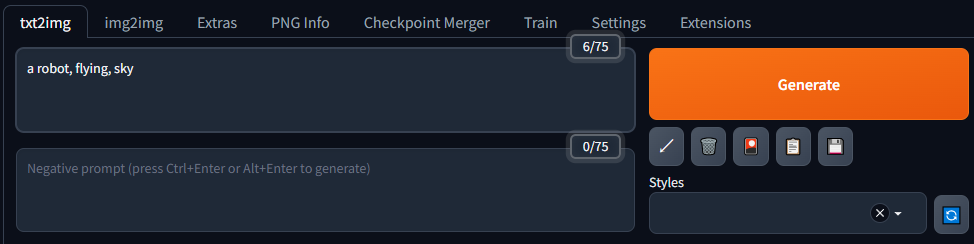
プロンプト(Prompt)に「a robot, flying, sky」と入力して、「Generate」ボタンを押します。なお、パラメータの部分は、Batch Sizeを5にして1度で生成される画像を5枚にした以外には、他の設定は特に変更していません。
しばらくすると出力エリアに以下のようなロボットが空を飛んでいるような画像が生成されました。

ネガティブプロンプト(Negative Prompt)についても少し試してみましょう。上記の画像では雲が画面内に入っていることが分かります。雲を表示しないように「cloud」というキーワードを入れてみます。

すると、雲がないような以下のような画像出力になりました。なお、複雑なプロンプトになるほど必ずキーワードが反映されるわけではないということは理解しておく必要があります。

ネガティブプロンプトは、生成したくない画像の特徴を入れることで望まない画像の出力を抑制できます。
例えば「worst quality」等を入れると品質が悪い画像を抑制できますし、「nsfw」というキーワードは、”not safe for work”という仕事中に見るには不適切なコンテンツという意味ですが、nsfwを指定することでアダルトや犯罪に関する出力を抑制するような効果があったりします。
生成AIではプロンプトの入力内容によって出力が大幅に変化します。これは、AIチャットサービスで有名なChatGPTでも同様ですね。
こういった技術はプロンプトエンジニアリングと言いますが、Stable Diffusionでも目的の画像を生成するためのよい書き方(呪文のようなもの)があり、色々な人が整理してまとめてくれているページが多く存在します。色々調べてみて参考にしてもらうとよいと思います。
まとめ
画像生成AIソフトウェアの一種であるStable Diffusion WebUIをローカル環境で動作させるための方法について解説しました。
Stable Diffusionは、入力したテキストをもとに画像生成が可能な生成AI(Generative AI)ソフトウェアの一種で「Stable Diffusion WebUI」はブラウザ上で画像生成を実行できるユーザーインタフェースです。
Stable Diffusion WebUIをローカルの環境で動作させるためにはPythonやGit、CUDA/cuDNNなど各種準備した上で構築する必要があります。本記事ではそれぞれの手順について紹介しました。
お持ちのPCでNVIDIAのグラフィックボードが搭載されている場合には、Stable Diffusion WebUIをローカル環境で構築すると色々試せて便利です。是非、参考にしていただいて最新の生成AIを試してみてもらいたいと思います。

プログラミング言語はこれまでC、C++、JAVA等を扱ってきましたが、最近では特に機械学習等の分析でも注目されているPythonについてとても興味をもって取り組んでいます。これまでの経験をもとに、Pythonに興味を持つ方のお役に立てるような情報を発信していきたいと思います。どうぞよろしくお願いいたします。
※キャラクターデザイン:ゼイルン様